What Is Duplicate Content? // Discover why duplicate content could be damaging your rankings without you even knowing!
 The issue of "duplicate content" is not a new phenomena. The problem has existed online since the internet began.
The issue of "duplicate content" is not a new phenomena. The problem has existed online since the internet began.
Of course, back when the web was in its infancy, duplicate content was only an issue for the author in terms of copyright infringement. The search engines (Google, Bing/MSN, Yahoo!, etc.) just weren't so concerned about it then.
However, these days, with the internet so hugely competitive and so open to abuse, the search engines have had to get smarter and work much harder at filtering the content they deliver in their search results. After all, the most important asset they have is the quality of their search results. Without useful search results, they would lose trust with their visitors and searches would drop off, which would directly effect their ability to generate revenue. This is where duplicate content becomes an issue...
The search engines do not want to deliver the exact same content multiple times for a single search query. This would not provide their visitors a quality and varied search experience.
The search engines fight this problem by implementing algorithms which examine the webpages they index to determine the similarity between them. If two or more webpages are determined similar enough to be considered duplicates, it's very likely that only ONE page will be delivered in their search results. The search engine chooses the webpage to rank based on it's authority. How exactly webpage authority and similarity is calculated is something no one outside the core search engineer teams at the search engines will ever know. Their search algorithms are closely guarded secrets and they do their utmost to prevent anyone from being able to reverse engineer them.
 "I now use DupeFree Pro at every step of article creation, from research gathering to writing, re-writing, and submission. It's hard to express the feeling of confidence it gives, knowing for sure that my articles will be working for me, not damaging my efforts.
"I now use DupeFree Pro at every step of article creation, from research gathering to writing, re-writing, and submission. It's hard to express the feeling of confidence it gives, knowing for sure that my articles will be working for me, not damaging my efforts.
I can't recommend this application highly enough. Thanks Guys!"
>> See more testimonials...
James Johnson
Pennsylvania, U.S.A.
www.OneTouchWeather.com
But like any automated process, these duplicate content filtering algorithms do not always get it right. And in fact, webpage authority can change over time, meaning someone can simply copy your content word for word and then make it appear as the authoritative source, resulting in them literally stealing your traffic as well as your content!
On top of this, it is not just others copying your content online that you need to worry about. You could actually be acting as your own worst enemy without even knowing it!...
The search engines look at duplicate content both outside and within a website's domain.
If your website has similar webpages internally, this can be a huge problem. The search engines apply the same duplicate content rules to your own website against itself. They will select the webpages they determine authoritative and index them whilst de-listing the rest! This is often a common problem for websites such as ecommerce shops where most of the content on every page stays the same with only a small change in the product title, description and price.
Are you wasting your time syndication the same content?
Syndicating content online is one of the most common methods used to market a website and gain rankings in the Search Engines. This ranges from article marketing via article directory submissions to submitting RSS feeds of your content. While these are fantastic methods for getting backlinks to you online properties, they can quickly fall victim to the duplicate content issue. If you are submitting the same article to multiple resources online, each submission will be seen as duplicate content by the Search Engines and they will begin to be de-indexed one by one. The number of back-links you've built up will start to disappear and all your efforts will have been wasted. It's extremely important to rewrite or mix-up your content as your syndicate it online. Doing this will ensure your syndicated content stays in the Search Engine indexes and keeps on working for you.
It's extremely important to rewrite or mix-up your content as your syndicate it online. Doing this will ensure your syndicated content stays in the Search Engine indexes and keeps on working for you.
Do you really want to leave it up to the search engines to choose which pages to send traffic to and which to ignore completely?
Content is what drives the web, and ultimately it is the livelihood of your website. As web-content publishers, we all spend countless hours and money getting great content written. Don't loose it to chance at the last hurdle. You need to stay duplicate content free ensuring your content is unique from the beginning and also not later being copied/plagiarized by others online.
But don't just take our word for it, check out what the experts are saying...
Over the years we've done our own share of tests and checks to see how duplicate content effects rankings and indexing. So we know first hand how important this issue is. However, there are various leaders in the Search and SEO fields who have been doing this for longer, and who, put simply, have the resources to do tests on a much larger scale. It's these expert guys and gals who first made us aware of the issue (and essentially the reason why DupeFree Pro was developed in 2005, back when it was just a simple in-house tool) and they really know what they are talking about. So, rather than let you take our word for it, we thought we'd share some of their thoughts and comments on duplicate content below so you can make your own mind up as well...
Ed Dale & Michelle MacPhearson 'Always Be Shipping' Webinar in 2011
Talking about duplicate content and author rank...
Ed Dale - "Things that used to be ok, like duplicate content or overlapping content, they're not going to be ok anymore."
Michelle MacPhearson - "And this is part of what Google did with the Panda update, is that they told us that things like duplicate content, things like over-lapping content, redundant articles - meaning an article about dog training, another article about dog obedience, an article about canine training, another article about canine obedience (laughs) - it's redundant, it doesn't add value to the web. And that is the kind of stuff that, with Panda, Google's looking to eliminate, and as we've seen, did eliminate quite a bit of it from the index..."
Google 'Panda' Algorithm Update
Matt Cutt's posts about Google's Panda algorithm update on the 28th January 2011...
"My post mentioned that...
"we're evaluating multiple changes that should help drive spam levels even lower, including one change that primarily affects sites that copy others' content and sites with low levels of original content."
That change was approved at our weekly quality launch meeting last Thursday and launched earlier this week."
Tim Converse Former Yahoo! Search Engineer & Content Classification Expert
WebmasterWorld 2006 presentation covering duplicate content...
"Why do search engines care about duplication? User experience, and they don't want to show the same content over and over again for the same query."
"Where does Yahoo! get rid of dupes? At every point in the pipeline, including crawl time, index time, and query time, they prefer to remove dupes at the time of the query."
"Dodgy duplication includes replicating content over multiple domains unnecessarily, "aggregation" of content found elsewhere on the web,"identical content repeated with minimal value. Others include scraper spammers, weaving/stitching (mix and match content), bulk cross domain apps, bulk dupe with small changes. How you can help Yahoo with this issue is by avoiding bulk dupe of your content over multiple domains, use the robots.txt to block bots, avoid accidental proliferation of dupe content (session IDs, 404s, etc.), avoid dupe of sites across many domains and when importing content from elsewhere ask do you own it and are you adding value."
Brad Callen SEO Software Developer
Talking about article marketing...
"Eventually Google will remove multiples of your content and ultimately reducing the number of backlinks to your website"
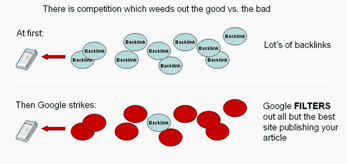
"...to decrease these issues with article marketing the easiest way is to rewrite your existing content in to multiple versions."
Vanessa Fox
Google Webmaster Central
Product Manager
Talking about internal duplicate content...
Skip to timestamp 16:15 for the relevant info:
Rand Fishkin:
"Duplicate content filter, is that the same or different from a duplicate content penalty?"
Vanessa Fox:
"What is going to happen is some kind of filtering. Because in the search results we want to show relevant useful results, and showing ten URLs that all go to the same page is not probably the best experience for users, what we are going to do is we’re going to index one of those pages..."
Adam Lasnik Google Search Evangelist
Talking about duplicate content on the official Google Webmaster Central blog...
"During our crawling and when serving search results, we try hard to index and show pages with distinct information. ...In the rare cases in which we perceive that duplicate content may be shown with intent to manipulate our rankings and deceive our users, we'll also make appropriate adjustments in the indexing and ranking of the sites involved. However, we prefer to focus on filtering rather than ranking adjustments."
"If you syndicate your content on other sites, make sure they include a link back to the original article on each syndicated article. Even with that, note that we'll always show the (unblocked) version we think is most appropriate for users in each given search, which may or may not be the version you'd prefer."
Matt Cutts Head of Google's Webspam Team
Talking about duplicate content at the 2007 SMX Seattle...
"...It's a deep issue and it's kind of a tough one too. So, really good question about claiming your own content. You always have to worry about how it can be spammed. What if someone innocent doesn't claim their content and then a smart spammer comes along and claims everybody else's content? When you've got your crawl frequency you've got to worry about people taking your content in between the time we've crawled your pages, that's a tricky thing."
"...one thing we've said, which is a pretty good rule of thumb, is if you do syndicate your content, try to make sure people know you're the master source of it."
Brad Fallon CEO of StomperNet
Advising on rewriting content to avoid duplicate content issues...
"When it comes to search engine rankings and SEO, Duplicate Content is a topic that's often misunderstood. Unfortunately, it's a very important topic - if you have too much "duplicate content" you can get killed, particularly when it comes to your rankings on Google."
"Search engines look at pages in 'sections' so changes that are not part of the "article body" will not count nearly as much. The more changes, the better. Private label articles will need close inspection by webmasters in the future. Articles that have only been changed a little bit will be picked up as duplicate content."
William Slawski
SEO Speaker & Consultant
SEObyTheSea.com
Talks about Google patent's and duplicate content...
"I've personally had some pages containing my own original content filtered out of search results and replaced by sites that duplicated my content. One, for instance was a blog home page with a PageRank of 5, being filtered out of Google's search results by a public Bloglines page containing excerpts of posts from that blog, with a PageRank of 0. ...Since that experience, I've felt like I have a personal investment in understanding why the search engines might filter out pages that they shouldn't be, and trying to make sure that similar experiences don't happen to other creators of original content that is copied by others."
"Google was granted a patent this morning (November 16, 2010) that describes how Google might identify duplicate or near duplicate web pages and decide which version to show in search results, and which ones to filter out. It's a process possibly close to what Google has been using for a while. But... identifying the original source of content can be a pretty hard problem to solve on the Web."
"Some duplication of content may mean that pages are filtered at the time of serving of results by search engines, and there is no guarantee as to which version of a page will show in results and which versions won't. Duplication of content may also mean that some sites and some pages aren't indexed by search engines at all, or that a search engine crawling program will stop indexing all of the pages of a site because it finds too many copies of the same pages under different URLs."
"When someone duplicates the content on your site, it may cause your pages to be filtered out of search results. ... Searching for unique strings of text on your pages, in quotation marks, may help uncover them."
"Many people create articles, and offer them to others as long as a link and attribution to the original source is made. The risk here is that the search engines may filter out the original article and show one of the syndicated copies."
Matt Cutts Head of Google's Webspam Team
Video blogging about Google detecting duplicate content...
"...we do a lot of duplicate content detection. It's not like there's one stage where we say, OK, right here is where we detect the duplicates. Rather, it's all the way from the crawl, through the indexing, through the scoring, until finally just milliseconds before you answer things."
"...and there are different types of duplicate content. There's certainly exact duplicate detection. So if one page looks exactly the same as another page, that can be quite helpful, but at the same time it's not the case that pages are always exactly the same. And so we also detect near duplicates, and we use a lot of sophisticated logic to do that."
"In general, if you think you might be having problems, your best guess is probably to make sure your pages are quite different from each other, because we do do a lot of different duplicate detection... to crawl less, and to provide better results and more diversity."
"Google does a lot of duplicate detection from the crawl all the way down to the very last millisecond, practically when a user see's things. And we do stuff that's exact duplicate detection, and we do stuff that's near duplicate detection. So we do a pretty good job all the way along the line, trying to weed out dupes and stuff like that. And the best advice I'd give, is to make sure your pages that might have near the same content, look as much different as possible..."
...
 Google's Matt Cutts' also gave some important advice from the 2006 WebmasterWorld PubCon site review session regarding avoiding duplicate content...
Google's Matt Cutts' also gave some important advice from the 2006 WebmasterWorld PubCon site review session regarding avoiding duplicate content...
"The wrong thing to do is to try to add a few extra sentences or to scramble a few words or bullet points trying to avoid duplicate content detection. If I can spot duplicate content in a minute with a search, Google has time to do more in-depth duplicate detection in its index."
Jim Morris/Scott Hendison Search Engine Seduction Show
Talk about real-life examples of duplicate content problems...
Skip forward to timestamp 12:20 in the video below:
"...Google was seeing that duplicate content in multiple places and it was deciding, not based on the date at which it was submitted, it was just deciding that based on the authority of eBay classifieds, based on the fact they are a big dog, they were giving them the original authorship rights to that content and bouncing the rest of his text in to the supplemental's. ... They were taking all his original content, crediting it to another place that he put it and that was really hurting his whole blog, indexing, page rank, any links he was putting in those blog posts to other areas of his site... As soon as he started rewriting his content he was able to get his pages fully indexed..."
"That extra 3 minutes that it took them to rewrite something unique, as soon as they started doing that, not only did their shopping cart or their content management system page, the actual property page, start to rank, but then they started getting an indented listing too."
"...especially with your titles and meta descriptions, make sure to vary those from page to page and not have them the same because otherwise you may not get the kind of rankings you want, or one of those, or two of those pages that have identical title tags and meta descriptions, are going to be shoved off in those 'click here to see the other results'..."
Andy Steggles CEO of SitePRTracker.com
Talking about Page Rank & duplicate content...
Skip to timestamp 3:10 for the relevant info:
Andy Steggles:
"I actually rewrote about a hundred property listings because of the duplicate content issue. The people that posted the listings had posted them elsewhere on different sites. So I rewrote a hundred just as a test and then monitored those hundred and guess what? ...the page rank went up to 4 from 0 for each one of them; more or less 3 or 4, something like that. So its a really good indication. It means Google has certainly acknowledged that 'hey hang on you've got content on here now that isn't duplicated all over the web and therefore we're going to give it more value'."
Mike McDonald:
"So do you think duplicate content is one of the leading issues...?"
Andy Steggles:
"I think duplicate content is a huge issue ... But, at least I know what the problem is so then at least I can now advise people when they upload content to 'hey don't just copy it from somewhere else, re-write it, make it unique'."
Nathan Anderson
SEO Expert & Coach
NathanAnderson.us
Blogs about keeping content unique...
"Google already gauges for unique content. You won't get far in their rankings without it. Yahoo and MSN have more trouble distinguishing, but it's obvious that they're catching up. Really, it won't be possible in the future to rank well in the search engines with non-unique content. Do whatever you can to re-write non-unique content on your sites, or your traffic is in jeopardy."
Andy Jenkins Former StomperNet CEO
Talks about the severity of duplicate content...
StomperNet launch video covering duplicate content:
"...I've got more words in my content container than in my content template, more than enough so the search engines judge this page different enough from the rest of my pages to count as worthy of an indexing. Doing this reduces 'same-ness' and by reducing 'same-ness' you dramatically reduce the potential for having a page flagged as duplicate content."
Andy in a previous StomperNet video:
"You might not think you're doing anything wrong with your site right now, which is exactly what everyone who has been punted from Google thinks, but 75% of the people that I've coached since 2004 have come to me with this very same issue because they've had it bad.
There's a concept in the SEO world called 'duplicate content', some say it's a penalty, it's more like a website death sentence. In fact the entire concept spawned a another lovely SEO term 'site death', yeah, it's that serious...
At it's most fowl, you're just gone, but the insidious nature of this penalty can mean your site can be suffering from it right now and you wouldn't even know it. Not only could your site start to slowly loose rankings, this penalty could keep you from ranking at all, for anything but your URL.
And it's bad, over the last 6 years I've had thousands of customers and the duplicate content is the biggest source of pain and suffering for both new and experienced e-business owners.
In fact one of the very first reports that I wrote for our paid StomperNet membership back in 2006 was about, you guessed it, duplicate content. It's a huge issue. ...The reality is, duplicate content could ruin your whole business."
Blogged by Andy Jenkins on April 20th, 2011:
"Duplicate content is one of the Internet frills that Google has been fighting for quite a while now. A lot of people who want to turn some quick profits in the web resort to direct copying or rewriting of other people’s original content without proper attribution. This is not only illegal; it also clutters up the web and deprives legitimate authors of the opportunities that should have come along with their hard work"
With all of the expert comments above, it's hard to deny that
duplicate content is a very real and current issue.
In fact, we could keep on researching and adding even more comments from other respected peers in the SEO and Search industries, but I think the above demonstrates the point well enough.
However, even though many of the comments above are from actual Google and Yahoo employees, it would be nice to have some concrete evidence that the search engines do in fact implement these anti-duplicate content procedures in their algorithms.
Well, luckily for us, the search engines file many patents which are readily available for anyone to read. And some of the patents they have filed strongly indicate they are thinking about, and likely implementing, systems to tackle duplicate content head-on...
PROOF: Filed Patents from Google & Microsoft

Google Patent: Detecting duplicate and near-duplicate files
The following extract is from one of the granted Google patents on duplicates...
"Improved duplicate and near-duplicate detection techniques may assign a number of fingerprints to a given document by (i) extracting parts from the document, (ii) assigning the extracted parts to one or more of a predetermined number of lists, and (iii) generating a fingerprint from each of the populated lists. Two documents may be considered to be near-duplicates if any one of their fingerprints match."

Google Paper: Detecting Near Duplicates for Web Crawling
Google Patent: Methods and apparatus for estimating similarity
An interesting paper from a Google employee (Detecting Near Duplicates for Web Crawling) provides an overview of processes to detect duplicate and near duplicate content on web pages. This paper contains a process that was developed by Moses Charikar, a Princeton professor, who has previously worked for Google. Moses Charikar is the inventor of an already granted Google patent which details methods to detect similar constant on the web: Methods and apparatus for estimating similarity
Google Patent Application: Detecting duplicate and near-duplicate files
Another Google patent application, by Monika H. Henzinger, discusses methods for detecting duplicate and near duplicate content across different web addresses. This patent application contains references to a variety of different methods, including Dr. Charikar's.
Patent Abstract:
"Near-duplicate documents may be identified by processing an accepted set of documents to determine a first set of near-duplicate documents using a first technique, and processing the first set to determine a second set of near-duplicate documents using a second technique. The first technique might be token order dependent, and the second technique might be order independent. The first technique might be token frequency independent, and the second technique might be frequency dependent. The first technique might determine whether two documents are near-duplicates using representations based on a subset of the words or tokens of the documents, and the second technique might determine whether two documents are near-duplicates using representations based on all of the words or tokens of the documents. The first technique might use set intersection to determine whether or not documents are near-duplicates, and the second technique might use random projections to determine whether or not documents are near-duplicates."
Google Patent: Detecting query-specific duplicate documents
This patent from Google describes a process for handling duplicates and is fundamental as it details a system for looking at snippets instead of pages - (the days of just changing a few sentences or adding a couple extra lines to duplicate content is likely over)...
Patent Abstract:
"An improved duplicate detection technique that uses query-relevant information to limit the portion(s) of documents to be compared for similarity is described. Before comparing two documents for similarity, the content of these documents may be condensed based on the query. In one embodiment, query-relevant information or text (also referred to as "snippets") is extracted from the documents and only the extracted snippets, rather than the entire documents, are compared for purposes of determining similarity."
Microsoft Patent: System and method for optimizing search results through equivalent results collapsing
This next extract is from a Microsoft patent application involving collapsing equivalent results for search results pages and discusses some of the signals that may be used to determine which results to show, and which to filter.
All Search Engine's want to avoid duplicative results filling up the top spots on search results pages. This patent application provides some insight into what search engines consider when choosing which pages to show, and which to hide...
Patent Abstract:
"A system and method are provided for optimizing a set of search results typically produced in response to a query. The method may include detecting whether two or more results access equivalent content and selecting a single user-preferred result from the two or more results that access equivalent content. The method may additionally include creating a set of search results for display to a user, the set of search results including the single user-preferred result and excluding any other result that accesses the equivalent content. The system may include a duplication detection mechanism for detecting any results that access equivalent content and a user-preferred result selection mechanism for selecting one of the results that accesses the equivalent content as a user-preferred result."
Microsoft Patent: Method for duplicate detection and suppression
Another patent application from Microsoft focuses upon the actual filtering aspect of duplication, as opposed to the detection part...
Patent Extract:
"...requiring l matching supersamples in order to conclude that the two objects are sufficiently similar, the value of l being greater than the corresponding value required in the previous method. One application of the invention is in association with a web search engine query service to determine clusters of query results that are near-duplicate documents."
"I am writing to tell you how impressed I am with DupeFree Pro. I just started using the program and it is awesome!!!!!
I write articles and have to check articles which may be close to the subject, I am writing about. The easy to use interface, is so well thought out and is real functional when breaking apart essays and assignments, then comparing the changes I have made.
Whether or not you write professionally, or only write for college or high school it will prove to be a valuable tool, on your computer system. ...I would highly recommend using this product."
>> See more testimonials...
Gary Owens
California, USA
The patents above display some hard evidence that duplicate content is a hot topic for the Search Engines.
And remember, these patents are only the ones we've read about. Who know's what else is unreleased and kept behind closed doors. Yet even just this set of patents alone, clearly demonstrates how worried the major search engines are about duplicate content negatively impacting their search results.
These patents also show how utterly complex and open to inaccuracies duplicate content detection is. As with most automated processes, duplicate content detection is ultimately a bit of a "gray science".
It's for these reasons you absolutely must stay clear of duplicate content in your published content online. It's just not worth the risks when the consequences of ignoring this issue ranges from the unknown to the down right disastrous.
And why leave this extra worry on your conscience when you can so easily avoid it with the right knowledge and tools?...
So, how can DupeFree Pro help you avoid duplicate content?
DupeFree Pro has been available for many years now. It's evolved from a private in-house app in 2005, to a basic free tool in 2006, and now, as the latest incarnation, a vastly improved, infinitely bigger and completely reworked version 2 release!
We originally created DupeFree Pro to help our writers rewrite our own existing content and PLR (private label rights) content in a way no other tool could. We found the other tools available just weren't practical for everyday efficient use in a real online content publishing business. So we were forced to create our own software with a very specific set of special features, that even to this day, still make DupeFree Pro so unique and powerful.
For example, with DupeFree Pro you have complete control over the duplicate content algorithm; no other tool offers anything like this. This allows you to set exactly how you wish content to be detected as duplicate content giving you a lot of flexibility for a variety of scenarios. Also, when rewriting content you can visually and precisely see exactly where the duplicate content is with the multicolor highlighting, right down to each matching text pair, so you can efficiently target and rewrite the duplicate content quickly and with total confidence (again, no other tool offers this level of targeting precision). It's features like these, that has enabled DupeFree Pro to help thousands of people from all kinds of backgrounds; writers, bloggers, article marketers, website owners, teachers, programmers and more. Check out all the user submitted testimonials to see how DFP has positively effected so many people from all over the world.
 "I was waiting and looking for DupeFree Pro for the last 2 years... I don't know how I got by without DupeFree Pro all this time.
"I was waiting and looking for DupeFree Pro for the last 2 years... I don't know how I got by without DupeFree Pro all this time.
I use DupeFree Pro to help me in my article marketing. I am so glad I bumped into the page that lead me to it. I love it and will be a client forever."
>> See more testimonials...
Marie Augustin
www.serendipity-astrolovers.com
However, DupeFree Pro v2 is more than just an upgrade...
DupeFree Pro v2 is a complete rebuild... from scratch!
We have started again, right from the beginning, using all the experience and feedback we've gained over the years while DupeFree Pro v1 was available. This has resulted in a massively improved and much more ambitious project. At the time of writing, the project has been in development for over a year and a half and will continue to be developed and evolved in to the future. We want DFP to remain the "go-to" tool for anyone wanting to keep their content, and ultimately their search engine rankings, safe from duplicate content.
Despite all the improvements, we have managed to keep DupeFree Pro accessible to everyone... We are managing to do this by using "add-on modules"
We realized not all the new functionality we are building in to DFP is relevant to all types of users, so rather than creating one massive software application with a huge price tag, we have split up the main functions of DupeFree Pro v2 in to separate "add-on modules". This means, as a DupeFree Pro user, you can choose to obtain only the add-on modules which provide the functionality you need. This keeps costs down for you and allows DupeFree Pro to be flexible and continue to grow with fantastic new functionality and features added via new add-on modules.
Click here to jump over to the homepage and check out the current set of DupeFree Pro modules to see how they can each help you fight duplicate content and protect your Search Engine rankings.

|
Tom Dunn Upstate New York, USA |
"I was using another article compare tool which I thought was pretty good, until it began to have some problems and I started to look elsewhere. This is when i found DupeFree Pro and man am I glad I did. DupeFree Pro is far superior to the one I was using in every way. I love the fact that you can specify how many words to search for and whether or not it spans the end of a sentence. Fantastic! I stopped using the other product and I am a big fan now of DupeFree Pro. I would not be without it. I use it to proof my articles that I re-write and it is a pleasure to work with and an invaluable tool. Get it today!" Bill Kernodle California, USA |
James Slack-Smith NSW, Australia |
 "My primary method of generating traffic is Article Marketing, so it's very important to me to avoid posting duplicate content as much as possible. DupeFree Pro gives me the ability to do just that, quickly and easily. When you write and post as many articles as I do, having a quality tool like DupeFree Pro is a real time and work saver. Thanks DupeFree Pro!"
"My primary method of generating traffic is Article Marketing, so it's very important to me to avoid posting duplicate content as much as possible. DupeFree Pro gives me the ability to do just that, quickly and easily. When you write and post as many articles as I do, having a quality tool like DupeFree Pro is a real time and work saver. Thanks DupeFree Pro!" "I would have expected to pay big $$$ for an application that compares rewritten articles with the original to ensure the search engines do not recognize them as duplicates. DupeFree Pro rocks. Not only does it calculate the percentage of duplicate content for articles that you have saved on your computer, it connects to the internet and checks for duplicate content with the big 3 search engines. Brilliant!"
"I would have expected to pay big $$$ for an application that compares rewritten articles with the original to ensure the search engines do not recognize them as duplicates. DupeFree Pro rocks. Not only does it calculate the percentage of duplicate content for articles that you have saved on your computer, it connects to the internet and checks for duplicate content with the big 3 search engines. Brilliant!"
Disclaimer
Every effort has been made to accurately represent our product and it's potential. Any claims made of actual earnings or examples of actual results can be verified upon request. The testimonials and examples used are exceptional results, don't apply to the average purchaser and are not intended to represent or guarantee that anyone will achieve the same or similar results. Each individual's success depends on his or her background, dedication, desire and motivation. As with any business endeavor, there is an inherent risk of loss of capital and there is no guarantee that you will earn any money.
Disclosure of Material Connections Between Advertisers and Endorsers
Testimonial providers may have received a promotional copy (and/or other material compensation), in order to facilitate their Honest opinion for their endorsement and may be a marketing affiliate for DupeFree Pro.
TekkTonix Home | TekkTonix Affiliates | TekkTonix HelpDesk | TekkTonix Customer & Affiliate Login/Registration Area
Privacy Policy | Terms Of Use | Subscriber Agreement | Software License Agreement | Affiliate Agreement | Earnings Agreement | Anti Spam
Copyright © 2012 - TekkTonix - All rights reserved